Наушники со встроенным локатором распознали выражение лица по форме щек
Американские инженеры разработали наушники, способные распознавать мимику лица пользователя. Для этого в каждый наушник встроен миниатюрный сонар, который с помощью звуковой эхолокации считывает информацию о движениях боковой области лица, после чего алгоритм машинного обучения восстанавливает выражение лица пользователя в реальном времени с высокой точностью. Эту информацию затем можно использовать, например, для создания анимированных аватаров в приложениях для общения. Статья с описанием устройства опубликована в журнале The Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies.
Технологии распознавания мимики лица человека, которые уже давно успешно используются для создания анимации персонажей в кино видеоиграх, постепенно проникают и в нашу повседневную жизнь. Например, компания NVIDIA предложила использовать распознавание выражения лица для снижения объемов данных, передаваемых по сети во время видеозвонков. Вместо того чтобы посылать все кадры, алгоритм сжатия посылает один кадр с лицом и данные о ключевых точках на нем, после чего компьютер на принимающей стороне анимирует этот кадр с помощью нейросети.
Эта и многие другие подобные технологии распознавания мимики обычно требуют, чтобы перед лицом постоянно находилась видеокамера, что может быть не всегда удобно. Для решения этой проблемы американские инженеры придумали технологию C-Face, которая с помощью встроенных в наушники двух камер и алгоритма машинного обучения способна распознавать мимику человека в реальном времени по движениям небольшой боковой области лица, попадающей в поле зрения устройства.
Несмотря на хорошие результаты в распознавании, устройство с двумя видеокамерами потребляло много энергии, зависело от условий освещенности и вызывало сомнения в безопасности использования, так как в поле зрения постоянно работающих камер могли попасть приватные данные. Поэтому инженеры из Корнеллского университета под руководством Чэня Чжана (Cheng Zhang) разработали новую версию этой технологии под названием EarIO, в которой вместо визуальной информации с камер используются данные звуковой эхолокации.

(e) Внешний вид прототипа наушников EarIO, (a) Динамик, (b) Плата с микрофоном, (c),(d) вид основной платы сверху и снизу
Ke Li et al. / Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2022
Прототип устройства выполнен в виде наушников-вкладышей, на каждом из которых есть выступающая пластиковая платформа с миниатюрным динамиком, излучающим в направлении боковой части лица непрерывный частотно-модулированный звуковой сигнал (FMCW) в диапазоне, неразличимом для слуха человека. Рядом с динамиками находятся микрофоны, принимающие отраженный от боковых контуров лица пользователя сигнал. Посылая множество последовательностей сигналов, можно получить профиль эха — последовательность изменяющихся во времени кадров, которая содержит информацию о расстоянии до окружающих поверхностей, от которых отражается звук. При разрешении локатора 0,385 сантиметров, устройство оказалось способно отслеживать даже небольшие деформации контуров лица в области наблюдения. Это позволяет уверенно идентифицировать большинство мимических выражений.
Записанное микрофонами эхо предварительно обрабатывается, чтобы выделить информацию, относящуюся только к лицу пользователя, отфильтровывая шумы и паразитные сигналы от фоновых объектов, находящихся на удалении. Затем вектор записанных в течение одной секунды данных отправляется на вход сверточной нейросети ResNet-34, предназначенной для классификации изображений, а после через полносвязный декодер. На выходе получают 52 параметра, которые разбиваются на две группы, соответствующие верхней и нижней половинам лица. Они затем используются для реконструкции мимики с помощью программного интерфейса Apple ARkit. Эталонные размеченные данные для обучения модели получают с помощью камеры TrueDepth смартфона iPhone 12. В процессе тренировки пользователь должен держать смартфон перед лицом и демонстрировать на камеру выражения вслед за появляющимися на экране подсказками.
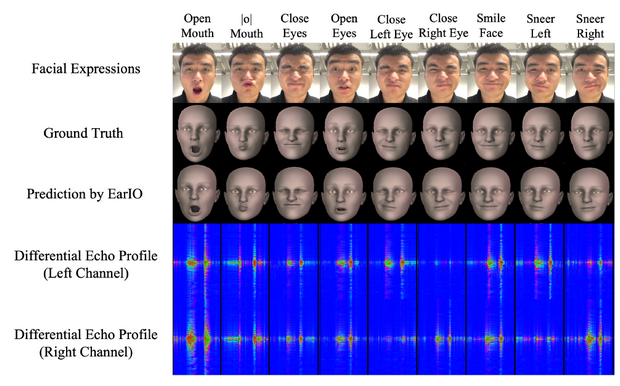
Изменение выражения лица вызывает отчетливые изменения эха
Ke Li et al. / Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2022

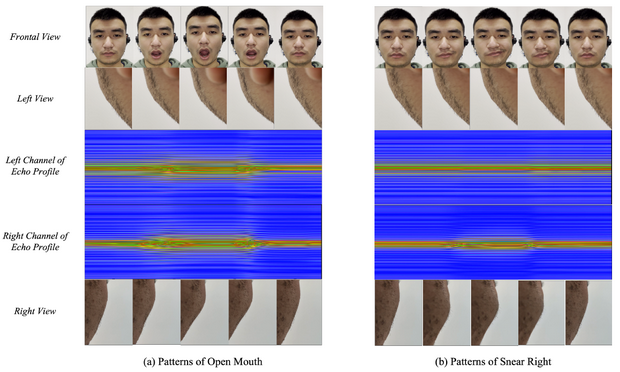
Изменение выражения лица вызывает отчетливые изменения эха
Ke Li et al. / Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2022
Инженеры создали две версии устройства: проводную, для удобства настройки и тестирования всех компонентов, и беспроводную версию, использующую для связи со смартфоном вариант технологии передачи данных Bluetooth с низким потреблением энергии. В качестве источника питания беспроводной версии прототипа используется аккумулятор емкостью 110 миллиампер-часов, которого хватает приблизительно на три часа работы. Разработчики отмечают, что EarIO потребляет около 154 милливатт, что оказалось значительно ниже, чем у предыдущей версии устройства, использующей две видеокамеры.
На данный момент прибору требуется несколько десятков минут тренировки, для того чтобы научиться распознавать мимику нового пользователя. По словам инженеров, в будущем они планируют внести улучшения для того чтобы значительно уменьшить время первоначальной настройки.
Считывать движения лица человека можно не только для того, чтобы определять его мимику, но и для распознавания речи. Ранее мы рассказывали об американских и китайских инженерах, который создали ожерелье SpeeChin, распознающее безмолвные команды на английском и китайском языках с помощью инфракрасной камеры, которая фиксирует движения подбородка.
Андрей Фокин
Источник: nplus1.ru


