Сколтех — новый технологический университет, созданный в 2011 году в Москве командой российских и зарубежных профессоров с мировым именем
Группа учёных из Сколтеха, Университета Шарджи и Казахского национального университета имени аль-Фараби выявили биологические маркеры клинической депрессии, с помощью которых можно добиться более объективной диагностики заболевания. Результаты исследования опубликованы в журнале Neurobiology of Stress.
Клиническая депрессия, или большое депрессивное расстройство, является сегодня второй наиболее частой причиной потери трудоспособности после онкологических заболеваний. Учёные ожидают, что к 2030 году она выйдет на первое место. По данным Всемирной организации здравоохранения, этой хронической болезни подвержены 280 миллионов человек по всему миру. Несмотря на это, диагностировать клиническую депрессию всё ещё сложно.
«Сейчас диагностика психических расстройств в основном осуществляется с помощью беседы пациента с врачом, заполнения опросных листов и оценивания результатов с помощью шкал. Иногда разные врачи могут по-разному интерпретировать результаты, возникает фактор субъективности. До сих пор в мире нет надёжных биомаркеров — объективных показателей предрасположенности к психическому заболеванию или его развития. Мы хотели найти такие биомаркеры, которые будут надёжными и при этом доступными. МРТ-исследование, например, можно провести не везде, а анализ крови многие стараются избегать», — рассказывает соавтор работы, старший преподаватель и руководитель исследовательской группы Центра прикладного искусственного интеллекта в Сколтехе Максим Шараев.
В рамках совместного с Университетом Шарджи проекта учёные использовали комплексные мультимодальные данные, которые характеризуют пациента с разных сторон — МРТ-исследования, электроэнцефалографию, анализ крови, генотипирование и транскриптомный анализ.
«Вероятно, эра простых биомаркеров заканчивается. Теперь нет какого-то одного критерия, который покажет, есть у человека заболевание или нет. Нужны комбинации этих маркеров, и их помогают находить методы машинного обучения. Мы получили комплексные данные и сделали такие модели машинного обучения, которые на основе этих данных смогут создать интегративные биомаркеры. Но перед тем, как объединить разные типы данных, мы исследовали каждый тип в отдельности, чтобы найти какие-то предпосылки для анализа, на что обращать внимание», — объясняет Шараев.
Опубликованная работа посвящена одному типу данных — транскриптомному, то есть анализу экспрессии генов в клетках, которые могут предсказать клиническую депрессию. Часть биомаркеров обнаружили с помощью машинного обучения и открытых баз данных, сравнивая показатели для пациентов разных национальностей. Данные транскриптомного анализа 170 пациентов с клинической депрессией и 121 здорового пациента параллельно изучали двумя разными методами — биоинформатики и машинного обучения.
«Стандартные методы биоинформатики помогают работать с многомерными данными при маленьких выборках, накладывать на них ограничения, фильтровать их и приходить к числу генов, которые затем можно проверять в лаборатории. Это стандартные подходы, которые основаны на классической статистике, но у них есть ряд недостатков. Например, может быть слишком много ложных срабатываний, у них достаточно долгое время сходимости, а часть важных признаков может быть пропущена. Мы в Сколтехе дополнили эти методы решениями машинного обучения. Взяв те же данные, мы настроили модели, добились высокого качества классификаций, а затем получили значимые признаки — гены, экспрессия которых влияла на результат», — комментирует Шараев.
Учёные получили наиболее значимые гены, сравнив результаты двух исследований. Такой подход позволил повысить их объективность, так как методы, используемые параллельно, основаны на разных моделях. После валидации результатов на независимой выборке их подтвердили и с помощью лабораторных исследований — анализа слюны 12 пациентов с клинической депрессией и 8 здоровых пациентов. С помощью атласа мозга Аллена также показали, что эти гены экспрессируются в различных участках мозга человека.
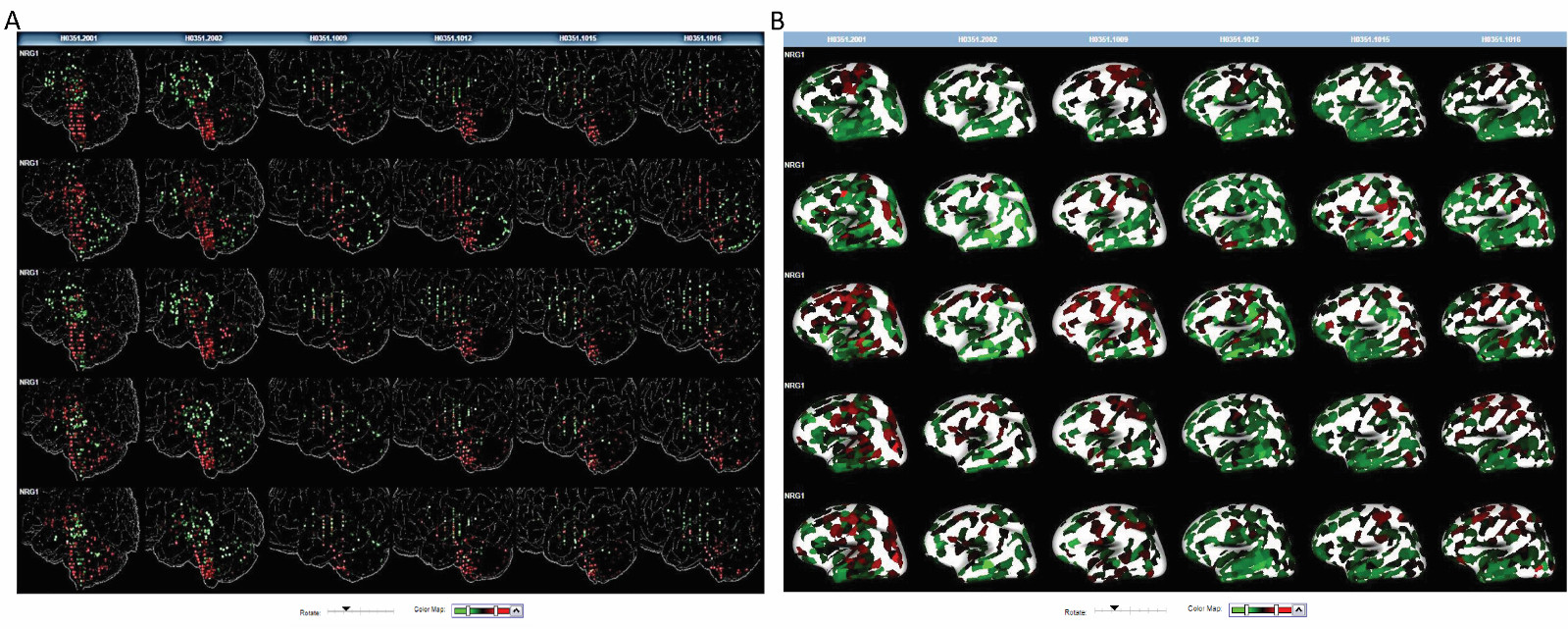
Изображение: экспрессия значимых генов в отделах головного мозга
«В дальнейшем можно расширять и уточнять набор этих генов для скрининга и быстрой диагностики. Всё это можно проводить по слюне. Не надо брать кровь или проводить сложные исследования. Для предварительного анализа этого достаточно, чтобы сделать какие-то выводы», — объясняет Шараев.
«Наше исследование показывает, как важно использовать искусственный интеллект в сочетании с методами биоинформатики для лучшего понимания молекулярных механизмов таких сложных болезней, как большое депрессивное расстройство. Открытие неинвазивных биомаркеров очень ценно как для пациентов, так и для клинических психиатров», — подытоживает первый автор исследования, профессор, директор Научно-инновационного центра точной медицины в Университете Шарджи Рифат Хамуди.

Исследование проведено в рамках совместного с Университетом Шарджи проекта Interpretable Artificial Intelligence and Deep Learning models based on integrative Neuroimaging and Genetics data for predicting abnormal emotional development.
Источник: www.skoltech.ru