AudioGPT — Взгляд в будущее создания музыки
С выпуском MusicLM в январе 2023 года как музыкантам, так и специалистам по данным стало ясно: ИИ здесь, чтобы изменить то, как мы делаем музыку. Всего несколько дней назад была опубликована следующая крупная модель звукового ИИ. В этой статье мы рассмотрим, почему я думаю, что эта модель может стать основой крупного технологического прорыва в производстве музыки .
В статье рассматриваются следующие вопросы:
- Что такое AudioGPT?
- Как это работает?
- Каковы его возможности и ограничения?
- Что это значит для будущего создания музыки?
Что такое AudioGPT?
AudioGPT — исследовательский проект группы китайских и американских исследователей, опубликованный в апреле 2023 года[1] . Но что он на самом деле делает и как он связан с моделями GPT? Давайте узнаем:
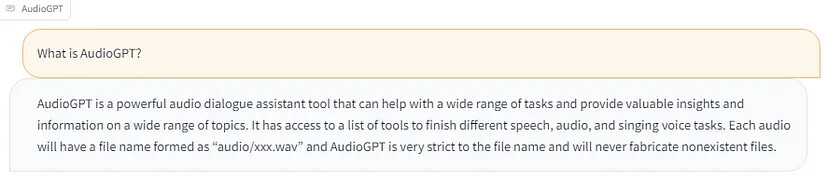
AudioGPT — диалоговый помощник
Как видно из скриншота, AudioGPT можно использовать в интерфейсе чат-бота, похожем на ChatGPT. Фактически, он работает так же, как ChatGPT для большинства диалоговых приложений. Одной из уникальных особенностей AudioGPT является то, что, помимо текста, чат-бот может обрабатывать речь в качестве входных данных, сначала транскрибируя аудио в текст. Следовательно, это настоящий диалоговый помощник, с которым вы можете разговаривать или писать, в зависимости от ваших потребностей.
AudioGPT может выполнять различные звуковые задачи
Диалоговые возможности AudioGPT являются только вспомогательной функцией. Его истинная цель — предоставить единый ответ для решения множества задач в области анализа и генерации звука. Вот некоторые из задач, с которыми он может справиться:
- Расшифровка аудио : описание содержимого аудиосигнала с помощью текста.
- Разделение источников: разделение аудиосигнала на разные события (голоса, шумы и т. д.)
- Изображение-в-аудио: создание звука, соответствующего содержимому изображения.
- Преобразование в аудио: создание певческого голоса с учётом текста, нот и длительности нот.
- Многие другие задачи , которые мы рассмотрим позже!
Круто то, что AudioGPT, в отличие от ChatGPT, умеет принимать и отправлять аудиофайлы. Например, когда я попросил AudioGPT сгенерировать определённый звук для меня, он создал звуки, экспортировал их в файл wav и отправил мне местоположение экспортированного файла.
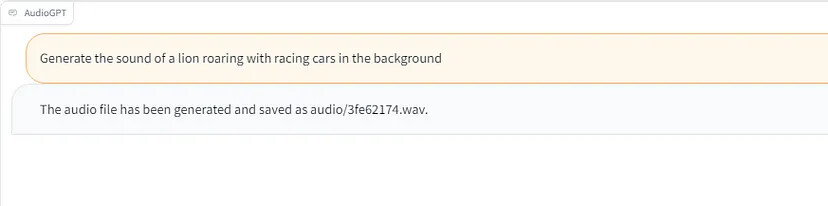
Прежде чем мы сможем понять значение этой технологии для будущего создания музыки, позвольте мне сначала показать вам, как на самом деле работает AudioGPT и каковы его сильные стороны и ограничения.

Как был реализован AudioGPT?
Хотя AudioGPT может показаться пользователю типичным чат-ботом с искусственным интеллектом, на самом деле под капотом происходит гораздо больше. Фактически ИИ чат-бота (ChatGPT) используется только как переводчик между запросом пользователя и другими моделями ИИ. Такие подходы уже существуют для других областей, таких как изображение ( TaskMatrix ) или текст ( LangChain ). Давайте посмотрим на иллюстрацию рабочего процесса AudioGPT, предоставленную авторами в их статье [1] .
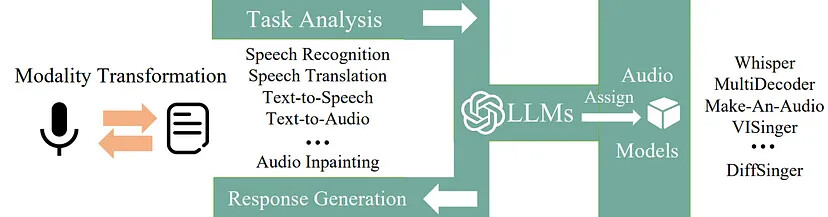
Как вы видите, рабочий процесс разбит на четыре разных этапа. Давайте кратко пройдемся по всем из них.
Шаг 1: Преобразование модальности
AudioGPT создан для обработки речи и ввода текста. Поэтому первый шаг — проверить, пишет ли пользователь текстовое сообщение или разговаривает с системой. Если ввод представляет собой речь, она расшифровывается и преобразуется в текст системой распознавания речи, подобной Alexa или Siri. Для пользователя этот шаг преобразования должен казаться плавным.
Шаг 2: Анализ задачи
При вводе текста ChatGPT берёт на себя управление и пытается понять запрос пользователя. Говорите ли вы «Создать wav-файл со звуковым эффектом грома» или «Дай мне звук грома»: ChatGPT отлично понимает разные формулировки одной и той же проблемы и сопоставляет запрос с конкретной задачей.
Шаг 3: Назначение модели
Как только ChatGPT понял запрос, он выбирает подходящую модель ИИ из набора 17 моделей, включенных в настоящее время в систему. Каждая из этих 17 моделей выполняет одну конкретную задачу очень специфическим образом. Поэтому крайне важно, чтобы ChatGPT понимал запрос, находил правильную модель и представлял запрос пользователя таким образом, чтобы модель могла его обработать.
Шаг 4: Генерация ответа
Как только соответствующая модель будет найдена и запущена, она сгенерирует выходные данные. Этот вывод может иметь всевозможные модальности (аудио, текст, изображение, видео). Вот где снова появляется ChatGPT. Он собирает выходные данные модели и представляет их пользователю таким образом, чтобы он мог их понять и интерпретировать. Например, текстовый вывод может быть передан пользователю напрямую, а аудиовыход будет экспортирован, и пользователь получит путь к файлу со ссылкой на экспортированный звук.
Память и история чата
Решить одну задачу — это здорово. Однако что действительно выделяется в этом подходе к чат-боту, так это то, что AudioGPT может просматривать всю историю разговоров. Это означает, что вы всегда можете ссылаться на запросы, вопросы или результаты из более раннего разговора и просить AudioGPT что-то с ними сделать. В некотором смысле это похоже на ChatGPT, но с возможностью приёма и отправки аудиофайлов.
Что может AudioGPT?
В этом разделе я хочу привести несколько примеров из статьи того, что может сделать AudioGPT. Это, конечно, не полный список, а лишь некоторые интересные моменты.
Генерация изображения в аудио

В этом примере AudioGPT просят сгенерировать звук, соответствующий изображению кота. Затем система отвечает местоположением экспортированного аудиофайла и визуализацией аудиосигнала. Мы не можем слушать этот пример из бумаги, но ответом, скорее всего, будет кошачий звук, похожий на шипение или мурлыканье. Под капотом изображение сначала снабжено подписью, а затем подпись изображения синтезируется в звуковой сигнал. Музыкантам может быть очень полезно создавать сэмплы для своей музыки, просто вводя изображение того, что они ищут.
Генерация певческого голоса

А это уже актуально для музыкантов! Если мы дадим модели текст вместе с информацией о нотах и длительности нот, она синтезирует певческий голос и отправляет звук обратно вам. Под капотом применяются современные модели синтеза речи (DiffSinger [2] , VISinger [3]) . Легко представить, как такого рода технологию можно было бы реализовать непосредственно в DAW, например, для создания певческих сэмплов для битов хип-хопа или даже бэк-вокала.
Извлечение звука

На основе текстовой подсказки AudioGPT определяет, где в звуковом сигнале происходит конкретное событие, и отсекает ненужную для пользователя часть звука. Вырезание сэмплов или звуков с использованием только словесных подсказок может оказаться невероятно полезным для музыкантов. Возможно, мы недалеки от того, чтобы сказать нашей DAW «извлечь наиболее эмоциональную часть этого семпла и сократить ее до одного такта», не выполняя никакой механической работы самостоятельно.
Разделение источников

Здесь AudioGPT предлагается разделить два динамика в аудиосигнале и вернуть оба извлечённых динамика по отдельности. В настоящее время в эту систему не включен инструмент разделения музыкальных источников. Однако легко представить, что вскоре мы сможем извлекать определённые инструменты или группы инструментов из аудиосигнала прямо внутри нашей DAW через интерфейс чат-бота.
Каковы ограничения AudioGPT?
Хотя эти примеры демонстрируют, как AudioGPT может создать основу для прорывных технологий в будущем, у него всё ещё есть много ограничений.
Он не был создан для музыки
В контексте этого поста важно отметить, что AudioGPT пока не является отличным инструментом для анализа или генерации музыки. Единственная реальная специализированная музыкальная модель — это модель синтеза певческого голоса. Некоторые другие модели способны воспроизводить музыкальные звуки, но они в первую очередь созданы для речи и звуков, а не для музыки.
Однако это не является ограничением системы как таковой. Напротив, это в первую очередь потому, что разработчики не решили включить в этот инструмент более специализированные модели музыкального ИИ. С текущим состоянием AudioGPT в качестве основы можно включать в эту систему всё больше и больше аудиомоделей или создавать отдельную музыкальную систему.
Это незавершённая работа
Из моего ограниченного опыта использования AudioGPT я уже могу сказать, что процесс назначения задач работает не так хорошо, как хотелось бы. Часто мой запрос неправильно понимают и называют неправильную модель, что приводит к совершенно бесполезному результату. Кажется, что всё ещё нужно провести некоторую оптимизацию, чтобы сделать эту систему всё более и более компетентной в понимании потребностей пользователя.
Кроме того, состояние звукового ИИ в целом по-прежнему сильно отстаёт, например, от состояния текстового ИИ. Большинство из 17 моделей, включенных в AudioGPT, работают довольно хорошо, но имеют очевидные ограничения. Следовательно, даже если назначение задач AudioGPT работает идеально, системы все равно будут ограничены возможностями базовых моделей.
Что это значит для музыки?
Помощники по композиции / производству AI
На данный момент AudioGPT никак не влияет на работу и жизнь музыкантов. Однако, по моим оценкам, в ближайшем будущем это изменится. Вот два шага, которые необходимо предпринять, чтобы сделать такие системы действительно преобразующими в этой области:
- Расширьте AudioGPT с помощью музыкальных моделей (разделение источников, тегирование, шумоподавление, звуковые эффекты и т. д.) или создайте отдельную модель MusicGPT, ориентированную на эти конкретные задачи.
- Разработайте плагины, которые позволят музыкантам получать доступ к AudioGPT (или MusicGPT) через интерфейс чата в их DAW.
Понятно, что это непростая задача. Особенно второй шаг может стать огромным препятствием для преодоления. Однако внедрение такого чат-бота в DAW может стать огромным конкурентным преимуществом для таких компаний, как Apple (Logic), Ableton или Image-Line (FL Studio). Усовершенствованная, ориентированная на предметную область и хорошо интегрированная версия AudiGPT может значительно повысить эффективность, свободу творчества и удовольствие от создания музыки.
Если в памяти системы хранятся все аудио- и MIDI-события текущего проекта, вы всегда можете перемещать, редактировать, комбинировать, удалять или улучшать эти события с помощью простых речевых или текстовых команд. Кроме того, некоторые вещи в творческом процессе легко выразить словами, но трудно выполнить вручную. Скажем, вы хотите, чтобы ваша песня звучала более «непринуждённо» и «расслабленно». Вы поворачиваете сотни ручек в выборе инструментов, микшере, цепочке эффектов и основных настройках? Или вы просто говорите своему ИИ-помощнику поворачивать ручки за вас? Я мечтаю о плагине DAW, который позволит нам генерировать звуки, применять эффекты, микшировать/мастерить наши треки, разделять инструменты, анализировать и маркировать нашу музыку и многое другое, и всё это в интуитивно понятном интерфейсе чат-бота. Такая система, несомненно, могла бы сделать нас всех более продуктивными и творческими в процессе создания музыки.
Улучшение, а не замена
За последние несколько месяцев такие модели поколений, как MusicLM, спровоцировали экзистенциальный страх у многих артистов. Хотя бесспорно то, что ИИ кардинально изменит музыкальную индустрию, я думаю, что AudioGPT — отличный пример того, как эти технологии могут дополнить, а не заменить нашу работу как музыкантов. Интерфейс чат-бота может быть очень полезен для создания, редактирования и перестановки звуков, но он не действует как автономный агент. Творчество, намерение и эмоции композитора или продюсера — вот что придает конечному продукту его ценность и значение.
В долгосрочной перспективе музыка, созданная людьми, всегда будет иметь для людей большую ценность, чем музыка, созданная искусственным интеллектом. Это просто потому, что музыка по своей сути является социальной и формой общения между людьми. Для большинства из нас не имеет значения, является ли музыка «сделанной вручную» в том смысле, что используются только акустические инструменты. Напротив, что действительно важно, так это то, что какие бы технологии ни использовались в творческом процессе, именно человек использовал эти инструменты контролируемым образом и как средство личного творческого самовыражения. В этом свете расширение функциональных возможностей AudioGPT и его интеграция в инструменты для создания музыки позволяет нам получать прибыль от технологий, повышающих скорость или творчество, сохраняя при этом нашу ценность и цель как композиторов.
Как я могу использовать AudioGPT?
Как программист
Как программист, вы можете просто клонировать репозиторий AudioGPT GitHub , установить все используемые модели, ввести свой ключ API OpenAI и начать работу. Это позволит вам использовать ВСЕ функции, представленные в статье.
Как обычный человек
Если вы не программист, вы всё равно можете использовать AudioGPT, хотя и в ограниченной степени, в этом веб-приложении HuggingFace . Для использования системы вам понадобится ключ OpenAI API. Вот учебник о том, как его получить. В зависимости от текущих условий использования OpenAI вам может потребоваться ввести информацию о вашей кредитной карте, чтобы иметь возможность использовать токен. Этот ключ необходим, потому что AudioGPT использует ChatGPT в фоновом режиме. Использование ChatGPT не очень дорого (0,002$ цента за ~700 слов на 23 апреля. См. документацию ). Тем не менее, если вы решите использовать этот ключ для AudioGPT, я рекомендую отслеживать затраты, вызванные системой, в вашей учётной записи OpenAI.
К сожалению, для меня это веб-приложение HuggingFace работает не очень хорошо. Когда я загружаю файлы, обычно возникает ошибка. Звуковые выходы иногда совершенно неправильные, хотя мою просьбу вроде бы поняли… Если у вас уже есть ключ API OpenAI, вам обязательно стоит его попробовать. Если нет, то я не уверен, что это веб-приложение стоит усилий по созданию учётной записи и ключа.
Рекомендации
[1] Хуанг, Ли, Ян, Ши и др. (2023) . AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head. архив: 2304.12995v1
[2] Лю и др. (2021) . DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism. arXiv:2105.02446
[3] Чжан и др. (2021) . VISinger: Variational Inference with Adversarial Learning for End-to-End Singing Voice Synthesis. arXiv:2110.08813
Источник: vc.ru


