Чатботы, трансформеры, беспилотный транспорт и все-все-все: экспресс-тур по городу ИИ
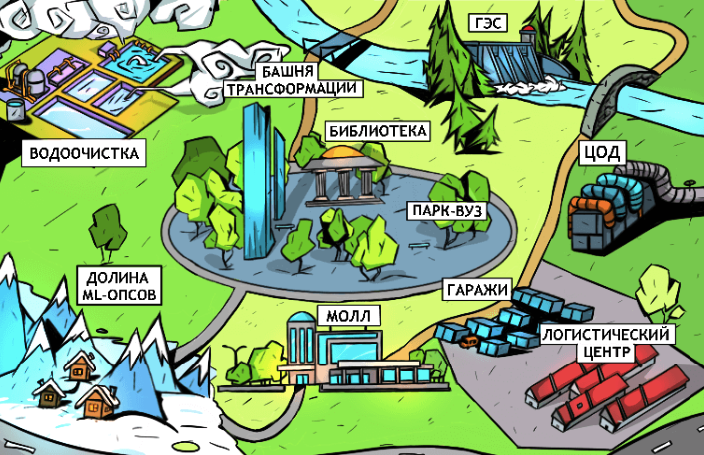
«Ничто не стареет так быстро, как будущее», — девиз конкурса «Технотекст 2021», в котором Ростелеком поддерживает номинацию «Искусственный интеллект». Мы понимаем, что изучать ИИ можно по-разному. Так, исследователи Gartner взглянули на него с точки зрения бизнеса и классифицировали направления ИИ по стадиям внедрения в производство. Пока одни технологии взбираются на пик хайпа, другие уже выходят на плато продуктивности — этап, когда радикальные инновации уже позади, но технологию ещё нужно допилить. Мы же посмотрим на ИИ как туристы. Представим, что ИИ — это город. Тогда отдельные технологии — объекты городской инфраструктуры. Мы прогуляемся по этому городу с гидами-экспертами, которые помогут понять, как работают технологии и для чего они нужны.
Большое железо для больших данных: гипермасштабируемые ЦОДы
На въезде, неподалёку от электростанции, нас встречает колоссальное сооружение, похожее на холодильник с солнечными батареями. Кажется, что оно никогда не закончится. Это — гипермасштабируемый ЦОД, построенный на месте бывшей промзоны. Площадь такого монстра — примерно квадратный километр. Сейчас в мире таких ЦОДов более пятисот, и они потребляют больше 200 ТВт в год.
Задача гипермасштабируемых ЦОДов — дать пользователям практически неограниченное увеличение вычислительных мощностей. Это нужно бизнесу, государству, частным лицам и интернету вещей. Аналитики утверждают, что спрос ещё подстегнут метамиры и виртуальные вселенные. Например, крупнейший клиент китайской Chindata, которая строит гипермасштабируемые ЦОДы, — это ByteDance, владелец TikTok. Виртуальным вселенным потребуется ещё больше памяти и полосы пропускания.
От простого к сложному: глубокое обучение (deep learning)
Вычислительная мощность — одно из главных условий успеха глубокого обучения. Чтобы разобраться в основных принципах работы глубоких нейронных сетей, достаточно вузовских курсов линейной алгебры и матанализа. Правда, архитектура современных сетей может быть довольно сложной. Но и здесь используется не какая-нибудь особенная математика, а эффективная адаптация вычислительных мощностей к особенностям задачи. Вспомним, как определяют глубокое обучение классики. Гудфеллоу, Бенджио и Курвилль в книге «Глубокое обучение» ставят во главу угла иерархию понятий, которую строит компьютер при обучении. При этом сложные понятия создаются на основе более простых. Граф, описывающий эту иерархию, — многоуровневый, или глубокий. А знания, как всегда в машинном обучении, приобретаются опытным путём. От человека не требуется формально описывать данные и строить признаки. Иными словами, этап «feature engineering» исключается.
Однако сразу возникают два вопроса. Во-первых, какие практические задачи решает глубокое обучение? Во-вторых, если переложить всю тяжесть работы с человека на компьютеры, то не окажется ли, что необходимые для глубокого обучения ресурсы есть лишь у гигантов, таких как Google, Amazon и Microsoft? Спросим у наших гидов-экспертов.
Возможности глубокого обучения безграничны. Вплоть до того, чтобы писать код за человека, рисовать картины и придумывать новые архитектуры глубоких нейронных сетей. Остаётся вопрос качества, который решается разработкой новых подходов, увеличением количества данных, ресурсных мощностей и времени, необходимого для решения. Тренировать системы глубокого обучения способны практически все. Всё зависит от архитектуры, объёма данных и нужного уровня качества.
Александр Мальцев
руководитель направления департамента анализа данных Ростелекома
Пример Говорящей Головы
Перед специалистами по традиционным практикам PR встают вечные вопросы — как вести блог на «Хабре»? Почему нельзя просто взять и разместить пресс-релиз? Почему хабрапользователи пишут мне такие ужасные комментарии?
Любя Любящая

Projects manager in Pixels
Получается, что использовать глубокое обучение может каждый, но результаты зависят от объёма данных и вычислительных ресурсов. Пустота на входе даёт и пустоту на выходе. Или, как сказано в Евангелии от Матфея, «кто имеет, тому дано будет и приумножится, а кто не имеет, у того отнимется и то, что имеет». Если данных мало, то их дефицит можно заместить только интеллектом человека.
Эти рассуждения наводят на два вопроса. Во-первых, какая аппаратная база требуется, чтобы глубокое обучение приносило пользу? Тысяча или миллион серверов? Во-вторых, каков эквивалент мозга одного человека в серверах? Спросим экспертов.
Самая крупная современная модель, GPT-3, училась на суперкомпьютере Microsoft Azure. Но огромные вычислительные мощности необязательны: выполнять глубокое обучение можно и на арендованных серверах, и на собственном компьютере (даже без GPU), и на смартфоне. Помогает подход transfer learning — берём знания, полученные крупными моделями авторства Google, Microsoft и других.
Оценить мозг в серверах не могу, но можно порассуждать. В нашем мозге около 80–100 миллиардов нейронов. GPT-3 имеет около 175 миллиардов нейронов, однако сравнивать некорректно: для имитации одного человеческого нейрона нужна как минимум тысяча искусственных. GPT-4, полагают, будет содержать около 100 триллионов нейронов. Но исходя лишь из этих чисел всё равно нельзя сказать, что она будет «умнее» человеческого мозга.
Александр Мальцев
руководитель направления департамента анализа данных Ростелекома
Пример Говорящей Головы
Перед специалистами по традиционным практикам PR встают вечные вопросы — как вести блог на «Хабре»? Почему нельзя просто взять и разместить пресс-релиз? Почему хабрапользователи пишут мне такие ужасные комментарии?
Любя Любящая
Projects manager in Pixels
И всё же процессоры, которые использует каждый из нас, не заточены под глубокое обучение и проигрывают специализированному железу в эффективности. А насколько незаменимы для глубокого обучения универсальные графические спецпроцессоры и интегральные схемы для deep neural network asics? Есть ли смысл производить их у нас и делается ли это?
В последнее время развиваются интегральные схемы для глубокого обучения, которые зачастую узконаправлены (допустим, заточены исключительно под умножение матриц), но делают работу быстрее и энергоэффективнее GPU.
Российских компаний в этой области мало. Недостаточно произвести схему — необходим софт. А разрабатывают софт и собирают схемы обычно разные компании в нескольких странах.
Александр Мальцев
руководитель направления департамента анализа данных Ростелекома
Пример Говорящей Головы
Перед специалистами по традиционным практикам PR встают вечные вопросы — как вести блог на «Хабре»? Почему нельзя просто взять и разместить пресс-релиз? Почему хабрапользователи пишут мне такие ужасные комментарии?
Любя Любящая
Projects manager in Pixels
Фильтр на входе: разметка и очистка данных

Глубокому обучению требуется не только «большое железо», но и большие данные. Настолько большие, что участия человека с опытом инжиниринга признаков не требуется. Однако это в идеале. На практике же подготовка данных не исчезла, а выделилась в отдельную отрасль.
Основная идея глубокого обучения — это иерархия понятий. А подготовку данных проще представлять в виде последовательности фильтров. Такая система есть и в нашем вымышленном городе.
На другой стороне реки — обширная территория водоподготовки, где речную воду направляют в бассейны и отстойники. Первым делом при помощи бурлящих пузырьков отпугивают рыбу. На механическом этапе очистки воду прогоняют через решётки, задерживая крупные примеси, а мелкие частицы отсеивают в песколовках. На биологическом этапе воду пропускают через отстойники с бактериями, которые превращают примеси в ил, а его убирают «илососы». На физико-химическом этапе вода обрабатывается коагулянтами, преобразующими оставшуюся взвесь в хлопья. И, наконец, после слоя кварцевых фильтров вода становится прозрачной и бесцветной.
Так же как очистка воды, разметка и очистка данных (data labeling) превратилась в большой бизнес. К примеру, стартап Scale AI оценивают в 7,3 миллиарда долларов. В компании трудится около 900 человек, а сумма венчурных инвестиций составляет 606 миллионов. Напрашивается вопрос: каковы перспективы очистки данных в качестве самостоятельного бизнеса в России? В каком формате это направление приживётся у нас?
С учётом политики импортозамещения это направление в России имеет большие перспективы. Яндекс.Толока — один из аналогов Scale AI, разработанный в России. На мировом рынке существует ещё около десяти крупных решений.
Аналоги появляются, потому что задач много и они разные: работа с видео, текстом или аудио. Исходя из задач, цены и удобства, пользователи выбирают разные продукты.
Александр Мальцев
руководитель направления департамента анализа данных Ростелекома
Пример Говорящей Головы
Перед специалистами по традиционным практикам PR встают вечные вопросы — как вести блог на «Хабре»? Почему нельзя просто взять и разместить пресс-релиз? Почему хабрапользователи пишут мне такие ужасные комментарии?
Любя Любящая
Projects manager in Pixels
Трудности перевода: трансформеры

В отличие от очистки данных, трансформеры (transformers) находятся на этапе исследований, и интерес к технологии только разгорается — как в индустрии, так и в прессе.
Представим, что мы перебрались через реку и попали в банк (bank). На самом деле — на берег (тоже bank — river bank). С помощью такого примера технологию трансформеров объясняют инженеры Google, которые её изобрели. Смысл фразы «I arrived at the bank after crossing the…» зависит от пропущенного в конце слова. Если это «road» (дорога), то перейдя её, мы, скорее всего, попадём в банк. Но если последнее слово в предложении — «river», то есть река, то, перебравшись через неё, мы выйдем на берег. В случае английского языка в обоих случаях будет использовано слово «bank». Переводчик-человек понимает смысл этого слова из контекста. А вот у ИИ общепринятого решения таких задач до недавнего времени не было.
Технология трансформеров как раз использует контекст. Каждому слову в предложении назначается вес, который называют «вниманием». Фраза переводится в несколько итераций, в ходе которых из нескольких значений слова «bank» выбирается правильное.
Изобретательность впечатляет, но есть ли у трансформеров применение за пределами машинного перевода? Механизм внимания — это новация или ребрендинг какой-нибудь канонической формулы?
Применение есть: архитектура transformer используется в CV (Computer Vision). Для обучения с нуля действительно нужны большие вычислительные ресурсы, но благодаря transfer learning можно дообучать готовую модель под конкретные задачи.
Если упрощать, то механизм attention помогает машине понять, к чему относится прилагательное, местоимение и т. п., а также — каковы более сложные взаимосвязи между частями входных и выходных данных (или только входных, если мы говорим о self-attention, основе архитектуры transformer).
Александр Мальцев
руководитель направления департамента анализа данных Ростелекома
Пример Говорящей Головы
Перед специалистами по традиционным практикам PR встают вечные вопросы — как вести блог на «Хабре»? Почему нельзя просто взять и разместить пресс-релиз? Почему хабрапользователи пишут мне такие ужасные комментарии?
Любя Любящая
Projects manager in Pixels
Больше чем слова: семантический поиск
В бесконечных потоках и водоворотах данных, мчащихся между торговыми моллами и логистическими центрами, нужна навигация. Поэтому наш виртуальный город удивит приезжих аккуратными указателями, адресными табличками едва ли не на каждом кустике и QR-кодами на стенах. Технология семантического поиска (semantic search), по мнению исследователей Gartner, выбирается из провала разочарования и завершает свою длинную историю победой. А до недавнего времени это направление казалось идеей без практических приложений. Что переломило судьбу семантического поиска? И где он выйдет на плато продуктивности — в торговых центрах B2B или в логистических центрах B2C?
Переход от поиска по ключевым словам к семантическому действительно долгое время казался теоретической идеей. Важный шаг произошёл в 2013 году, когда создали ПО word2vec. Инструменты для создания векторно-семантических моделей существовали и ранее, но word2vec стал прорывным, в первую очередь благодаря удобству использования, открытому исходному коду и скорости работы. Всё новые и новые подходы лишь улучшали качество поиска, помогая использовать контекст и дополнительные параметры (допустим, предыдущего поиска, геолокации, времени года и многие другие).
Сегодня тяжело отнести данную задачу однозначно к B2C или B2B, она даже встречается в M2M, используется успешно и давно, чем можно объяснить её широкое распространение. Как говорил Чеширский кот: «Кто ищет, тот всегда найдёт… если правильно ищет». А ищут ежедневно все: и люди, и машины.
Александр Мальцев
руководитель направления департамента анализа данных Ростелекома
Пример Говорящей Головы
Перед специалистами по традиционным практикам PR встают вечные вопросы — как вести блог на «Хабре»? Почему нельзя просто взять и разместить пресс-релиз? Почему хабрапользователи пишут мне такие ужасные комментарии?
Любя Любящая
Projects manager in Pixels
На всякого мудреца довольно простоты: чат-боты

По торговой части города нас сопровождают чат-боты (chatbots) — интеллектуальные компьютерные системы онлайн-помощи пользователям, имитирующие человеческое общение. Вежливая настойчивость ботов кажется искусственной: они механически следуют чётко заданному набору инструкций. Но от глубокого обучения и трансформеров ожидают повышения интеллекта ботов.
Как долго чат-боты будут оставаться неестественными? Скоро ли появятся видеоботы, похожие на обычных клиентских менеджеров и продавцов? Смогут ли они пройти расширенный тест Тьюринга и стать неотличимыми от людей не только по тексту, но и по картинке?
Нельзя говорить, что чат-боты сейчас примитивны. Существуют сложные разговорные системы ИИ, с которыми пользователи могут пообщаться, например «Маруся» от VK и «Алиса» от Яндекса. Сложность реализации зависит от целей: люди, обращающиеся в чат-бот Ростелекома, не просят рассказать анекдот или сделать заказ в ресторане, поэтому создатели адаптируют ботов под конкретные предметные области, которые могут быть и сложными, и простыми.
Большинство текущих подходов основаны на принципе rule-based. Чат-боту необходимо понять из сообщения намерение пользователя (интент). Далее бот строит диалог на основе бизнес-логики, внешних инфосистем и интеграций.
Интент можно определить по ключевым словам или сложнее — обучая быстро принимать сложные решения на основе большого количества данных и больших вычислительных ресурсов — чтобы бот отвечал быстро.
Второй важный момент — скрипты (сценарии), которые создаёт человек. Они не должны быть слишком сложными, чтобы не запутывать пользователя, и должны использовать уже полученную информацию (допустим, имя, адрес, номер телефона), чтобы не переспрашивать в дальнейшем. Наконец, они должны покрывать большинство запросов пользователя и иметь гибкий интерфейс для изменения под новую бизнес-логику.
Для нешаблонного ответа, покрывающего запросы пользователя, необходимы сложные интеграции с внешними системами. Если клиент хочет узнать баланс, то можно указать ссылку на сайт или описать путь получения баланса в приложении. Но вряд ли человека удовлетворит такой ответ. Именно для ситуаций вроде получения баланса необходимо настроить интеграции, что зачастую небыстрый процесс, особенно в крупных компаниях.
Последний момент — это генерация разнообразных ответов на одни вопросы. Например, прощание с пользователем: можно придумать формулировки, учитывающие имя, время суток, ранее заданные вопросы и другие параметры. Всё это влияет на «интеллект» чат-бота.
Пройти расширенный тест Тьюринга чат-боты не могут, но и не пытаются. Более сложные разговорные системы, не соответствующие rule-based-подходу, не так широко применимы из-за трудности настройки под конкретную бизнес-логику с учётом интеграций и в основном ограничиваются «болталками» на общие темы. Видеоботы возможны: уже есть системы генерации видеоновостей от Сбера. В нескольких поликлиниках используются роботы-ассистенты, помогающие уточнить определённые вопросы.
Объединить системы генерации видео и функционала чат-бота — задача вполне выполнимая, но большинство клиентов обращаются в чат приложения или мессенджера либо в контакт-центр. И лучше развивать эти каналы, чем тратиться на генерацию видео.
Александр Мальцев
руководитель направления департамента анализа данных Ростелекома
Пример Говорящей Головы
Перед специалистами по традиционным практикам PR встают вечные вопросы — как вести блог на «Хабре»? Почему нельзя просто взять и разместить пресс-релиз? Почему хабрапользователи пишут мне такие ужасные комментарии?
Любя Любящая
Projects manager in Pixels
Рано сдавать в архив: обработка текстов на естественном языке (NLP)
С пользователями общаются текстом и голосом, поэтому лингвистические корпуса, архивы и библиотеки в нашем городе расположены в самом центре. Не займут ли их место видеоархивы? Ведь кажется, что новые поколения всё меньше читают и пишут…
Не согласен, что поколения меньше читают и пишут. С развитием соцсетей и мессенджеров количество текста в интернет-пространстве только растёт. Растёт и желание пользователей писать в чаты компаний, где можно не ждать ответа на линии, а получить спустя время уведомление, где ответы бота или оператора остаются в истории и к ним всегда можно вернуться. Помимо этого, задача обработки текста на естественном языке не ограничена только текстовыми каналами связи. Аудиоданные переводятся в текст, с которым далее необходимо работать.
Александр Мальцев
руководитель направления департамента анализа данных Ростелекома
Пример Говорящей Головы
Перед специалистами по традиционным практикам PR встают вечные вопросы — как вести блог на «Хабре»? Почему нельзя просто взять и разместить пресс-релиз? Почему хабрапользователи пишут мне такие ужасные комментарии?
Любя Любящая
Projects manager in Pixels
Альтернатива реинжинирингу: интеллектуальное принятие решений
В центре делового квартала высится башня трансформации. Её вершина обычно скрыта в облаках, и именно там принимаются решения.
Интеллектуальное принятие решений (decision intelligence) ляжет в основу управления организацией при помощи данных. При переходе к управлению по данным можно было использовать два подхода. Первый — это реинжиниринг системы с созданием единого хранилища или единого информационного пространства. Второй — научить ИИ пользоваться зоопарком существующих систем: это и есть decision intelligence. Специалисты Gartner полагают, что полноценное распространение технологии займёт около пяти лет. А сейчас преобладают простые частные решения.
К примеру, в последние дни марта проводит IPO израильская компания Rail Vision, технология которой подаёт машинисту сигнал тревоги, когда обнаруживает вблизи от состава подозрительный объект. Эта система использует машинное обучение и данные от нескольких видеокамер в разных частотных диапазонах. Система разделяет опасные объекты на ряд классов, включая людей, животных и автосредства. И возможно, она лучше машиниста.
Ковер-самолёт: беспилотный транспорт

Транспорт в целом — и железнодорожный, и автомобильный, и авиация — большой рынок приложений ИИ. Поэтому удивляет, что беспилотные транспортные средства (autonomous vehicles) исследователи Gartner разместили в провале разочарования. До выхода на плато продуктивности — не менее десяти лет. Где же главный барьер — в самом ИИ, сопутствующих технологиях (таких как аккумуляторы и дальномеры), инерции производителей и потребителей или неготовности законодательства?
Основная причина разочарований — это завышенные ожидания. Все ждали автоматизированный транспорт без водителя и внешнего оператора.
Несмотря на разочарование, технология проходит этап становления. Ассоциация SAE (Общество автомобильных инженеров) выделяет пять уровней автономности транспортного средства: неавтономный (1), частично автономный (2), условно автономный (3), высокоавтономный (4) и полностью автономный (5). Мы сейчас на втором уровне: определённый функционал в управлении может взять на себя автоматика автомобиля — круиз-контроль, умные ассистенты. Но с точки зрения закона машиной управляет человек. На полигонах и на определённых территориях РФ переходят к третьему уровню автономности: можно ненадолго передать управление автомобилем, но отвечает за всё по-прежнему человек.
Недавно правительство приняло постановление «Об установлении экспериментального правового режима в сфере цифровых инноваций и утверждении Программы экспериментального правового режима в сфере цифровых инноваций по эксплуатации высокоавтоматизированных транспортных средств». Право развивается вслед за технологиями. Машины Яндекса справляются с автономным перемещением на закрытых территориях (внутри Иннополиса) на пятом уровне автономности — то есть без водителя.
Иван Колемасов
руководитель направления департамента анализа данных Ростелекома
Пример Говорящей Головы
Перед специалистами по традиционным практикам PR встают вечные вопросы — как вести блог на «Хабре»? Почему нельзя просто взять и разместить пресс-релиз? Почему хабрапользователи пишут мне такие ужасные комментарии?
Любя Любящая
Projects manager in Pixels
Всё и сразу: композитный ИИ
При столкновении с практикой красивые архитектуры ИИ нуждаются в адаптации, которая может занять годы. Поэтому технологии ИИ постепенно комбинируются и интегрируются. Подход композитного ИИ (composite AI) предполагает использование всего инструментария машинного обучения: очистку данных, обработку естественного языка (NLP), графы знаний, глубокое обучение и многое другое. Вряд ли один MLOps или дата-сайентист способен освоить все подходы. Означает ли это, что применять композитный ИИ смогут только большие команды консалтеров из крупных корпораций? И где взять специалистов — готовить в вузах или непосредственно в компаниях? В нашем воображаемом городе их обучают в кампусе нового типа — в городском парке, среди дубов и платанов. Университетских корпусов и аудиторий больше нет, они возникают лишь в моменты виртуальных конференций. Лаборатория будущих ML-опсов — это гараж, а стипендия — венчурные инвестиции.
Здесь мы заканчиваем нашу краткую экскурсию по городу ИИ. В статье мы рассказали не обо всём, наверняка есть и другие важные объекты. Предлагаем обсудить их в комментариях.
Источник: habr.com


