О дельфинах, аллигаторах и лингвистической интуиции ИИ
Системы машинного обучения намного умнее, чем мы думали
Весь мир уже знает историю про языковую модель Google LaMDA, якобы, прошедшую тест Тьюринга, убедив инженера Google Блейка Лемуана в том, что она не только разумна, но и обладает сознанием.

Журналисты оторвались на хайпе вокруг этой истории. А специалисты разошлись во мнении.
Большинство думает, как Гэри Маркус (когнитивист и автор книги «Перезагрузка ИИ»).
Все, что делает LaMDA, «это сопоставление шаблонов, взятых из массивных статистических баз данных человеческого языка. Шаблоны могут быть крутыми, но язык, на котором «говорят» эти системы, на самом деле, бесмыслен».
В то же время главный научный сотрудник OpenAI Илья Суцкевер в своем твите утверждает, что «может быть, сегодняшние большие нейронные сети немного сознательны».
Всё упирается в два ключевых вопроса—могут ли компьютеры понимать:
• Что за понятие стоят за словом?
• В каком контексте слово используется?
Опубликованное в Nature исследование осторожно намекает:
да—в принципе, могут.

Слова языка отражают структуру человеческого разума, позволяя нам обмениваться мыслями. Однако язык может представлять лишь подмножество нашей богатой и детализированной когнитивной архитектуры.
Авторы задались вопросом, какие виды общих знаний (нашей семантической памяти) фиксируются значениями слов (лексической семантикой).
Чтобы понять это, авторы исследовали известную вычислительную модель, которая представляет слова в виде векторов в многомерном пространстве, так что близость между векторами слов аппроксимируют семантическую связь.
Поскольку родственные слова появляются в сходных контекстах, пространство векторного представления слов (Word embedding) можно изучать на основе шаблонов лексических совпадений в естественном языке.
Человеческие суждения о сходстве объектов сильно зависят от контекста и включают множество различных семантических признаков.
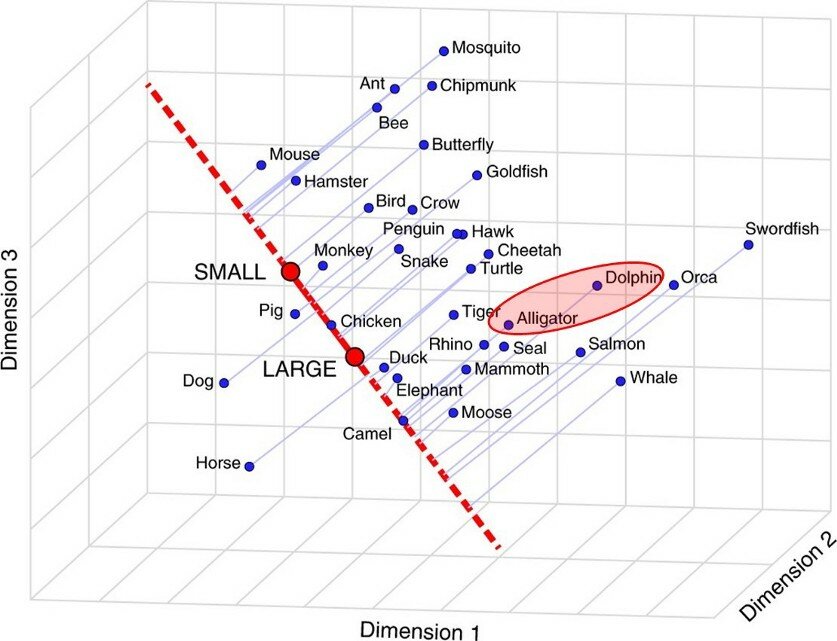
Например, дельфины и аллигаторы—это близкие понятия?
- С одной стороны, да—они живут в воде и похожи по размеру.
- С другой стороны, нет—они сильно непохожи умом и агрессивностью.
Чтобы понять, насколько стоящие за понятиями объекты близки, нужна система шкал: маленький-большой, умный-глупый, опасный-безопасный и т.д.
Авторы разработали технику, которую они назвали «семантической проекцией» слов-векторов на линии, которые представляют различные характеристики объекта (маленький-большой и т.д.)
Этот метод, аналогичный интуитивному размещению объектов “на ментальной шкале” между двумя крайностями, восстанавливает логику человеческих суждений по целому ряду категорий объектов и свойств.
В результате обширного пула сравнений суждений людей и компьютеров, было доказано, что векторное представление слов наследует множество общих знаний из статистики встречаемости слов и может гибко манипулировать ими для выражения контекстно-зависимых значений.
Исследователи обнаружили, что для многочисленных объектов и контекстов их метод оказался очень похожим на человеческую интуицию.
Например, что «тяжелая атлетика» и «фехтование» похожи тем, что и то, и другое обычно происходит в помещении, но различаются с точки зрения того, сколько интеллекта они требуют.
Постойте,—скажет здесь читатель поста. Ведь это же очень близко к пониманию слов, а не просто статистический анализ их встречаемости в обширном пуле текстов.
Авторы работы тоже так считают:
«Оказывается, эта система машинного обучения намного умнее, чем мы думали; она содержит очень сложные формы знания, и это знание организовано в очень интуитивную структуру»,—говорит один из авторов. «Просто отслеживая, какие слова сочетаются друг с другом в языке, вы можете многое узнать о мире».
Значит ли это, что Суцкевер ближе к истине, чем Маркус?
Получается, что это не исключено.
#Семантика
________________________
Ваши шансы увидеть мои новые посты быстро уменьшатся до нуля, если вы не лайкаете, не комментируете и не делитесь в соцсетях
Источник: zen.yandex.ru


