Сбор и разметка данных: как готовить, чтобы ваш ИИ говорил спасибо
Использование алгоритмов машинного обучения становится всё более актуальным методом для решения, как научных проблем, так и потребностей бизнеса. Спектр задач для ИИ на современном IT-рынке достаточно широк и включает в себя как решение вопросов контроля качества на производствах, так и обеспечение безопасности на объектах, отслеживание усталости и внимательности сотрудников, сбор и обработку большого объема статистических данных для выявления ошибок в работе технических объектов и предотвращения инцидентов. Подобные задачи возможно решать с помощью большого разнообразия методов, в том числе и при помощи машинного обучения. Достаточно часто компаниям, внедряющим ML (machine learning), приходится сталкиваться именно с задачами компьютерного зрения, решение которых происходит при помощи сверточных нейронных сетей.
Создание и обучение нейросети является достаточно сложным процессом, в котором задействована большая команда специалистов различного профиля (начиная от девопс-инженеров для развертывания серверов и окружения, дата-инженеров, подготавливающих датасеты к обучению, и завершая дата-саентистами, которые превращают всю предыдущую работу в магию). Принцип работы нейронной сети по своей сути заключается в преобразовании суммы входной информации в значение единственного выходного результата. По итогам инициации алгоритма можно сделать вывод о том, правильно ли нейросеть преобразует полученные сигналы. Именно поэтому базой для любой сети в первую очередь являются качественно подобранные и обработанные входные данные.
Текущие запросы на внедрение автоматизированных систем наиболее часто оказываются связаны именно с анализом фото- или видеофайлов. Это обуславливается не только простотой получения исходных данных (практически все современные производства и компании имеют системы видеонаблюдения), но и тем, что подобный формат позволяет собрать максимальное количество информации – визуальные средства отражают гораздо больше специфических свойств и характеристик объекта. Однако для грамотного функционирования каждая нейросеть должна пройти процесс первичного обучения, то есть научиться распознавать изображения с заранее зафиксированными значениями. Это один из ключевых этапов создания эффективной системы по анализу образов, где важную роль играет такое понятие, как разметка данных.
Сама по себе разметка является предварительной обработкой, к примеру, изображений, делающей информацию доступной для понимания нейросетью. В процессе разметки к исходному изображению или видеофайлу прикрепляются метаданные – определенные теги, которые несут в себе информацию о конкретных свойствах того или иного объекта. Сложность данного процесса заключается в том, что для создания качественного набора исходных данных (датасета), необходимо разметить тысячи изображений по заданной тематике, чтобы расширить визуальную вариативность и избежать проблем со «слепотой» нейросети в ходе работы в реальных условиях.
В настоящее время существует большое количество открытых датасетов — изображений с выделенными на них объектами в виде дополнительного файла с аннотацией, которые содержат в себе, как правило метку (название) класса и координаты, которые занимает контур объекта на данном изображении. Для обучения сверточных нейронных сетей размеченные данные подаются в нужном формате для конкретно решаемой задачи по-разному. Данные метки позволяют алгоритмам запоминать очертания объектов, цвета, формы и в дальнейшем находить их на новых снимках, которые будут передаваться системе с объектов эксплуатации.
Правильность и аккуратность разметки данных является одним из ключевых элементов в процессе обучения нейросети – выделение ряда определенных объектов позволяет сфокусировать «зрение» на конкретной задаче. Разметка производится с разным уровнем точности в зависимости от сложности и класса решаемой задачи. Для одного случая может быть достаточно выделить разметку прямоугольниками (bounding box’ами), а для другой более сложной задачи подобная точность разметки может оказаться недостаточной, что отразится на результате. В таком случае можно применять выделение объектов по контуру — сегментацию каждого объекта для более точной передачи информации о том или ином фрагменте на каждом снимке. Также важно отметить, что для пилотной разработки проектов может быть достаточно сортировки данных по разным папкам без выделения на них конкретных объектов и каких-либо дополнительных меток.
Создание датасетов для задач фото- и видеоаналитики может производиться несколькими способами с применением различных технологий в зависимости от поставленных задач и имеющихся ресурсов. Можно выделить ряд стандартных методов разметки, результаты которых чаще всего передаются командам разработки:
1. Прямоугольная разметка. Данный вид обработки изображений является одним из наиболее простых вариантов выделения объектов на фотографиях для отнесения их к тому или иному классу. Подобная разметка является самым быстрым методом и позволяет значительно сократить время, затраченное на обработку. Однако стоит отметить, что в формате сложных проектов, где требуется высокая точность выходных данных, подобный вид разметки может оказаться недостаточным и снизит качество работы итоговых алгоритмов.
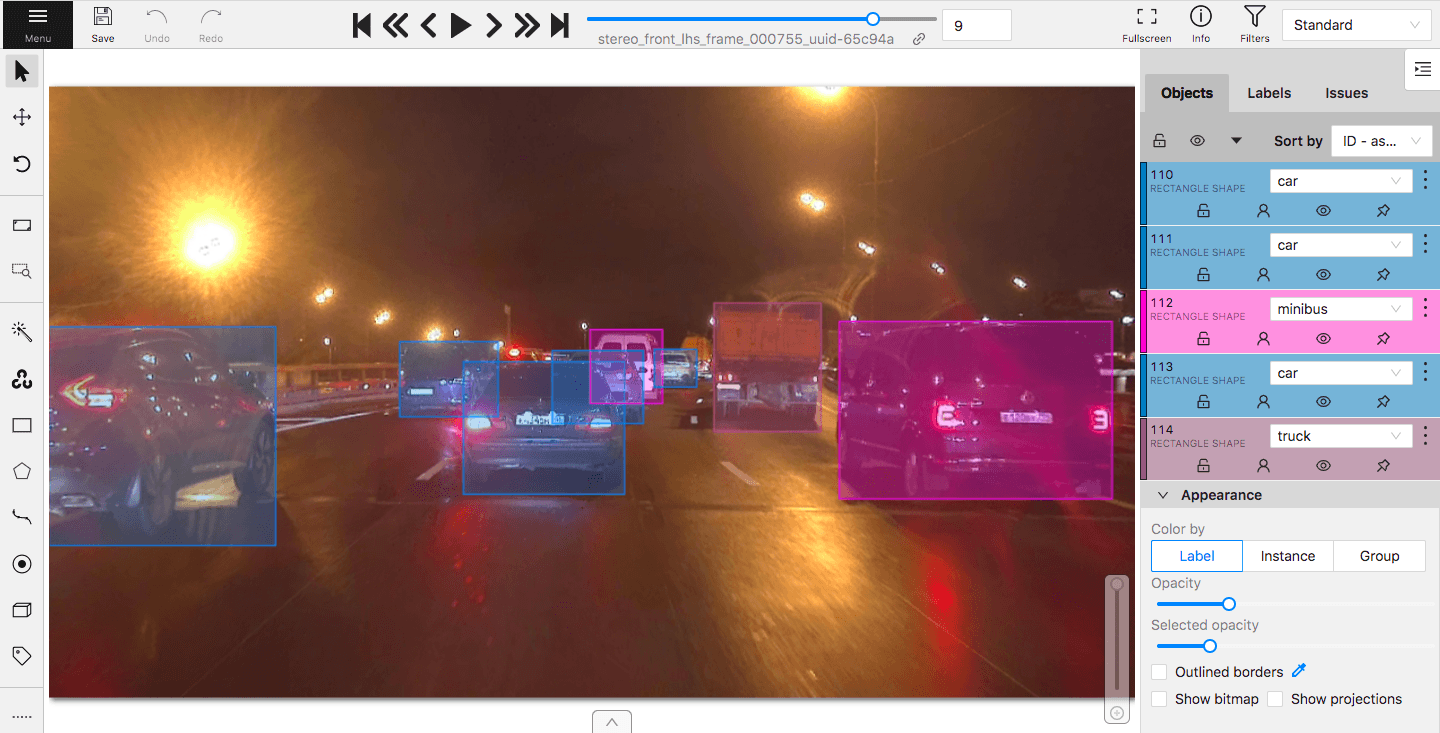
2. Проставление меток. Подобный метод позволяет создать алгоритм, способный выделять несколько свойств объекта согласно проставленным на нем мульти-меткам. Так один объект может обладать несколькими различными свойствами, определяемыми программой, что соответственно будет причислять его как подходящий к нескольким группам. Такая разметка изображений дает возможность создать более быстрый процесс подготовки данных для работы алгоритма, в котором в зависимости от условия объект будет или не будет учтен, но имеет одну из самых больших погрешностей в качестве работы итоговой системы.
3. Выделение полигонов. При использовании данного вида разметки на изображении полностью выделяются точные границы объектов, что позволяет нейронным сетям и алгоритмам получать наиболее «чистые» данные. При углубленной обработке изображений возможно также выделение рёбер, вершин и граней объекта, для создания 3D модели объекта. В ходе обработки изображения каждому пикселю присваивается своё значение, согласно которому алгоритм определяет границы объекта, а также его принадлежность к определенной группе. При этом есть два подхода в зависимости от решаемой задачи. При первом все объекты, относящиеся к определенной группе, будут рассматриваться программой как один (semantic segmentation). Однако в некоторых случаях применяется и метод случайной сегментации (instance segmentation), когда алгоритм распознает на изображении каждый отдельный объект вне зависимости от его отношения к конкретному классу. Разметка под задачи сегментации является достаточно сложным и долгим процессом, однако, в свою очередь, заметно повышает обучаемость нейросети и расширяет её ценность благодаря использованию менее зашумленных данных.

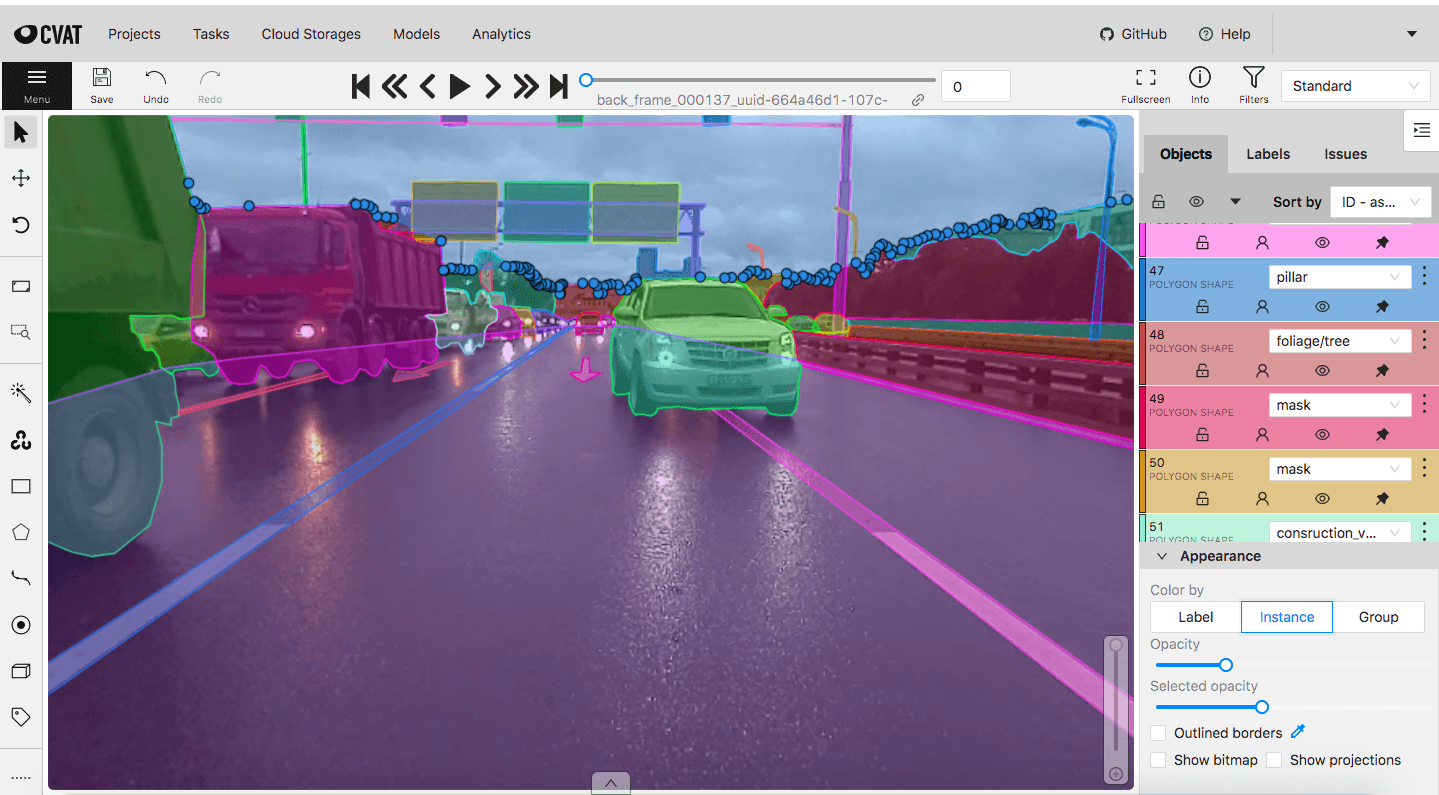 Разметка полигонами Neurocore AI lab
Разметка полигонами Neurocore AI lab
4. Ломаные линии (polylines). Отдельный класс разметки, который выделяется в стандартных средствах сервисов для выделения объектов, которая является наиболее удобной для выделения дорожной разметки, что можно увидеть и на снимке с полигонами, там тоже применяется данный подход.
5. Множества точек. Данная разметка полезна для решения задач поиска ключевых точек тех или иных объектов, обычно применяется для решения задач классификации лиц: отличить одного человека от другого. Также применяется для определения позы человека, по координатам отдельных точек можно распознавать позу тела, положение пальцев и т.п. по видео.

Рассматривая особенности работы с датасетами на примере кейсов нашей компании, хочется отметить, что появляется всё больше специфических нишевых задач, решение которых невозможно с помощью уже существующих наборов. Для их решения необходимо наличие возможности сбора дополнительных партий кадров, без которых решить задачу распознавания не представится возможным. В зависимости от решаемой бизнес проблемы приходится разрабатывать сценарии сбора данных и писать целые гайды для специальных актеров. В них описываются разнообразные действия, которые необходимо совершать на видеозаписях и фотографиях, чтобы входные наборы данных для обучения систем компьютерного зрения были наиболее разнообразными.
Если переходить к реальным примерам, то для одного из наших проектов, разрабатываемого для борьбы с гэмблингом, стояла задача создания системы распознавания и определения подлинности лиц людей. Цель проекта – отличать реальное лицо человека от поддельных. Например, от фото его лица на бумаге или видео на телефоне, в том числе и deep fake’а для пресечения обмана системы распознавания лиц, которая применяется в целях обеспечения безопасности и защиты от мошенничества.
Перед тем как собирать такие данные, мы начали мониторить открытые наборы данных и нашли лишь небольшие примеры в gitlab’ах, кусочки тестовых кадров, чего, конечно, было недостаточно. Либо находились разные научные организации, которые предоставляли доступ по лицензии без возможности использования в коммерческих целях, и не факт, что они еще оперативно смогли бы предоставить доступ. Также доступ часто был платным и стоил достаточно больших денег. Дедлайны приближались.
Купить рекламу Отключить
В конечном итоге для решения существующих проблем мы поставили себе целью собрать собственные данные: развесили по офису камеры на разной высоте, с различным уровнем освещения и ракурсами для получения многообразных примеров биометрических атак. Напечатали по 1000 фото лиц людей для каждой из 4х рас — монголоиды, негроиды, европеоиды и австралоиды с разбивкой по полу. Было сложно…
Если переходить к процессу сбора, то один человек сидел за компьютером и запускал запись с той или иной камеры. А другой в этот момент выполнял разные движения с маской лица: подходил ближе/дальше, левее/правее. Так мы фиксировали краевые сценарии, ловили блики, пытались обмануть систему распознавания лиц. И перед камерами почти неделю длился «маскарад»:

Таким образом мы собрали море кадров с «атаками» и успешно решили поставленные бизнес-заказчиком задачи.
Еще одним примером, где нам нужны были данные — была система распознавания автомобильных номеров. Как найти нужные фотографии в интернете и разметить?
Мы начинали с поиска вручную, но это было катастрофически медленно и мы решили написать парсер для одного из сайтов, чтобы автоматизировать данный процесс. В итоге за несколько дней было собрано и обработано порядка 100 тысяч изображений машин с номерами, что позволило нам провести их разметку, обучив таким образом систему. Еще одним источником получения готовых данных часто являются хакатоны, которые достаточно часто самостоятельно предоставляют датасеты с готовой разметкой для решения прикладных задач в короткие сроки. На одном из таких мероприятий мы получили доступ к 10 000 фотографий с размеченными номерами и марками автомобилей с автострад, которые использовались для фиксации нарушений ПДД. Так что хочется подчеркнуть важность участия в таких мероприятиях, где кроме возможности получить ценные призы и лавры можно найти и другие полезные артефакты.
Данная статья изначально задумывалась как рассказ о нестандартных подходах к получению и обработке данных — о том как самым неожиданным образом AI-рынок нуждается в талантливых актёрах для формирования качественных датасетов. А что если в будущем на сцене будут играть только роботы, а по-настоящему крутые актёры станут незаменимыми специалистами по подготовке новых уникальных событий для систем ИИ?
Однако все пошло не по плану. В процессе подготовки мы заметили, что в сети недостаточно детально описаны и сами виды разметки с их особенностями. Поэтому щедро сдобрили первую часть теорией. Так что to be continued, дорогие читатели… В продолжении статьи поговорим о профессии будущего — специалист по разметке данных. Разберемся кто они такие — какие навыки нужны, чтобы научиться размечать? Как правильно выстроить рабочий процесс? И с какими нестандартными кейсам приходится сталкиваться на современном AI-рынке?
Источник: vc.ru


