Искусственный интеллект
История развития искусственного интеллекта
Сразу с появлением первого компьютера ученые начали придумывать, как научить его думать по-человечески. Первая конференция, посвященная искусственному интеллекту (ИИ), состоялась еще в далеком 1956 году. С этого момента начинается история дискуссий об ИИ, его ограничениях и возможностях.
Маленькие дети учат язык «на слух». Они слышат разговоры взрослых, запоминают слова, начинают воспроизводить слова самостоятельно и следуют интуитивно воспринятым правилам использования языка. Если они ошибаются, то взрослые поправляют их — примитивная обратная связь. Ребенок быстро запоминает: если мама говорит о себе как о субъекте, то использует «я» и ставит его в начало предложения. Если же она говорит о себе как об объекте, то использует слово «меня» в конце фразы.
Взрослые учат новый язык иначе. Сначала они запоминают слова и правила построения предложений и только после этого начинают практику.
На самых ранних стадиях изучения ИИ профессиональное сообщество разделилось на два лагеря:
- Первые считали, что ИИ должен развиваться методом проб и ошибок, самостоятельно выявляя правила поведения и при необходимости корректируя их. В научной терминологии этот «детский» путь называется статистическим распознаванием образов.
- Вторые считали, что в ИИ необходимо изначально заложить правила поведения со всеми их сложностями и исключениями. Этот «взрослый» путь обучения получил название символического подхода.
Сначала казалось, что «символисты» более успешны. У них получилось создать основанный на правилах ИИ, который мог доказывать математические теоремы. Однако позже выяснилось, что другие задачи остаются для такого ИИ невыполнимыми. Например, он оказался непригоден для распознавания речи, перевода текстов с одного языка на другой, классификации изображений и т. д. Самые лучшие решения с ИИ, базирующиеся на символическом подходе, выполняли задачи хуже человека, и к концу 1980-х в этом направлении появился застой.
Проблема символического подхода оказалась в том, что невозможно запрограммировать абсолютно все правила.
В английском языке есть правило: прилагательные в предложении должны следовать строгому порядку: «мнение — размер — возраст — форма — цвет — происхождение — материал». То есть будет правильным сказать «крупный пятилетний вороной конь» и совсем неправильным — «пятилетний крупный вороной конь». Тем, кто изучает английский язык, очень сложно запомнить и применять это правило. Но странная вещь: люди, для которых английский язык родной, всегда употребляют прилагательные именно в таком порядке. При этом они часто не знают об этом правиле и чаще всего не могут его сформулировать.
Таким образом, подход, основанный на правилах, может быть применим в каких-то узких случаях: при доказательстве теорем, вычислениях, игре в шахматы. Но при решении более сложных задач он окажется неэффективным, потому что в них задействовано гораздо больше правил и все их невозможно учесть.
Исследователи из «детского» лагеря пошли иным путем. С 1950-х они пытались научить машину так же, как учат детей: с помощью опытов, повторений и обратной связи. В то же время возникает такое направление искусственного интеллекта, как машинное обучение.
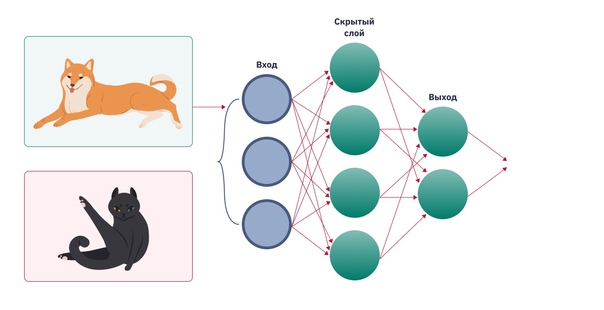
В 1957 году был создан перцептрон — устройство, моделирующее процесс человеческого восприятия. Задачей перцептрона стала классификация изображений, например он должен был отличить картинку с собакой от картинки с кошкой.

Именно в конце 1950-х годов были сформулированы почти все основные идеи в сфере нейронных сетей и искусственного интеллекта. Проблема состояла в том, что на тот момент у ученых не было технологий (вычислительных мощностей), чтобы получить результаты, которые могли бы применяться на практике. Такие технологии появились лишь в последние 20 лет — и мир увидел результаты.
1997: IBM Deep Blue обыграл чемпиона мира по шахматам.
2011: IBM Watson победил в ТВ-игре «Jeopardy!».
2016: Google DeepMind обыграл чемпиона мира по игре в го.
2017: OpenAl обыграл чемпиона мира по компьютерной игре Dota 2.
На последние два десятилетия приходится серьезное развитие сферы искусственного интеллекта. Причины прорыва:
ИИ: разбираемся в ключевых понятиях
Многие слышали термины «искусственный интеллект», «нейронные сети», «машинное обучение», «глубокое обучение», но не все смогут объяснить, как они соотносятся и в чем различаются.
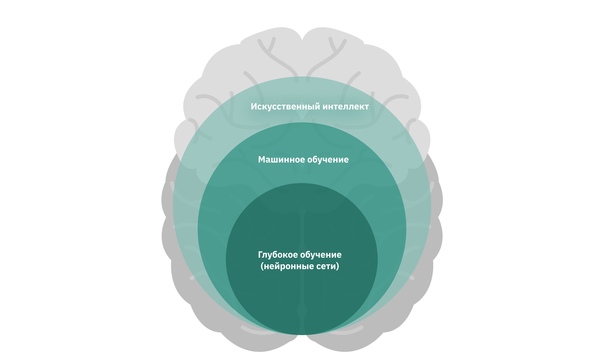
Сегодня нет финально устоявшегося определения искусственного интеллекта, но для нашей текущей задачи (разобраться в понятиях) можем привести следующее.
Искусственный интеллект — группа методов, которыми пользуются для решения различного рода задач. Некоторые из этих методов включают алгоритмы на основе машинного обучения.
Машинное обучение — это вид компьютерных алгоритмов, в которых алгоритм «учится» решать задачу. На прошлом шаге приводился пример алгоритма машинного обучения, который классифицировал фотографии с кошками и собаками: если ему дать тысячи таких фотографий, «ругать» за ошибки и «поощрять» за правильные ответы, то в какой-то момент он «научится» правильно классифицировать их.
Глубокое обучение является подвидом машинного обучения. При глубоком обучении всё происходит так же, как и в машинном: алгоритму дают данные и учат на них, ругая за ошибки или поощряя за правильные ответы. Разница лишь в том, что при глубоком обучении используются более сложные математические модели и алгоритмы.
Наверняка раньше вы слышали о нейронах применительно к человеческому мозгу — и это неспроста. Искусственная нейронная сеть работает по тем же принципам, по которым функционируют нейроны нашего мозга.
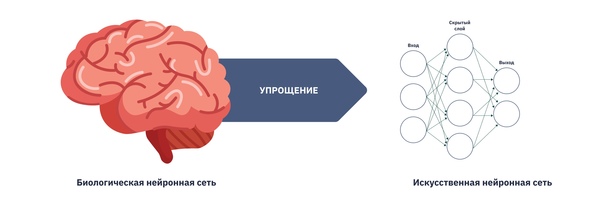
Нейросеть состоит из нескольких слоев нейронов, каждый из которых определяет какой-то определенный аспект. Например, когда нейросеть «читает» изображение кота, то один слой может выявить «четыре ноги», другой слой — «наличие хвоста», третий — «наличие усов», четвертый — «форму ушей».

Источник: m.vk.com